编译器的基本架构图
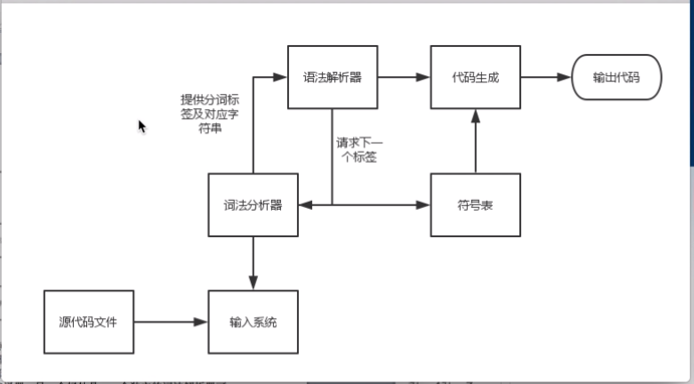
输入系统的作用将源文件从磁盘或者内存中读入,词法解析器与输入系统进行交互,通过输入系统获得源代码文件的内容,如果输入系统是一个独立的模块,通过固定接口和词法解析器进行交互,这也输入系统的修改和维护就会十分灵活。
输入系统的效率决定整个编译系统的效率,例如C语言,C语言的库函数将数据读入程序的过程中,有三次拷贝,一是从磁盘将数据拷贝到操作系统,二是将数据从操作系统拷贝到y一个FILE结构中,三是将数据从FILE结构拷贝到程序的内存中,这些拷贝需要耗费时间和空间,所以需要专门的输入系统。
输入系统应该具备以下特点:
- 输入过程要尽可能的快,尽力减少不必要的拷贝
- 支持多个字符的预读取和回放
- 当解析当前分割的字符串时,上一个解析过的字符串需要容易的获取
- 磁盘读写要足够便捷
输入系统的内存模型

startBuf指向缓冲区的起点End指向缓冲区的物理结束位置endBuf指向缓冲区的逻辑结束位置,数据最多存储到endBuf处MAXLEX指分割后字符串最多长度,每次从磁盘读入缓冲区数据量是MAXLEX的倍数next指向下一个要读取的字符
词法解析器工作过程中的缓冲区状态
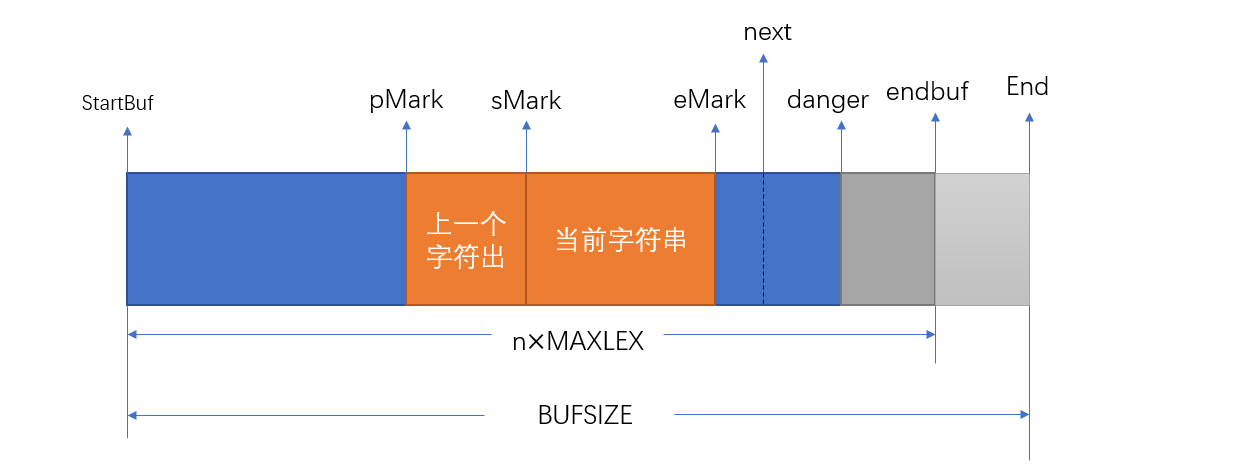
pMark上一个被解析的字符串的起始位置sMark当前被解析字符串的起始位置eMark当前被解析字符串的结束位置sMark-pMark上一个字符串的长度eMark-sMark当前解析字符串的长度
当next的值接近danger时,表明缓冲区内的有效数据很快被读完,当next指针越过danger时,会触发一次flush操作
flush操作
pMark到endBuf间的数据整体平移到startBuf处,平移的距离pMark-startBuf